RMQ advanced configuration
This page provides information about advanced configuration scenarios and troubleshooting.
Content Syncing
While transactions are possible with RabbitMQ, they are complicated and slow down publishing. Ideally, the same activation message would be received by all instances at the same time, but this is technically very difficult to achieve and does not add much advantage in any event.
What is important however is that a Magnolia instance knows when a node is out of sync with another node, and that the load balancer knows which node is late. This is achieved by recording the time stamp and latest message state.
Whenever a message has been consumed and the content activated on the instance, the instance stores the message id (which is a long that is incremented) and the date the message was activated.
| Instance | Message ID | Timestamp |
|---|---|---|
Public 1 |
|
|
Public 2 |
|
|
Public 3 |
|
|
This information is either sent to the load balancer or made available over a servlet. The goal is that the load balancer knows which instance is behind and by how much. In the example above the load balancer controlling tool knows that Public 1 and Public 2 are synced. It can decide to wait for Public 3 to sync, and if this does not happen, to alert the systems administrator or trigger the creation of a new instance.
SyncState and SyncStore mechanism
The Magnolia RabbitMQ implementation introduces the concepts of SyncState and SyncStore to achieve content synchronicity between public instances.
The mechanism is basically a counter that is incremented when each activation message is sent. The counter is sent in the message header. When the receiving instance gets the message, the instance increments its own activation counter. This means that two public instances which have different SyncStates are out of sync until the counters once again have the same number.
The load balancer calls the REST service of the public nodes and in this way knows which public node is most up to date and which one is out of sync.
| State | Reason | Action |
|---|---|---|
REST service is not responding. |
Public node down. |
Remove from the pool. |
Rest service’s sync state is 0. |
Public Node is up but completely out of sync. |
|
|
Public node is working but under heavy load. |
Remove public node temporarily from the pool until <x. |
| The load balancer also knows when the public instances are getting activated. SyncStates are persisted to the JCR. |
Guaranteeing synchronicity
The Dynamically Weighted Least Connections Algorithm on your load balancer guarantees synchronicity and ensures that public instances do not get too far out of sync..
The load balancer plays a big role in this. During a very big and long activation process, the load balancer can decide to redirect the traffic to the instances which have the highest and most equal ids. This increases traffic on these instances, which in turn slows down the activation process. Instances with initial low and unequal ids now have a higher chance of reaching the same state as the instances under load.
The algorithm creates a kind of "auto-damping" system that slows down instances by giving them more traffic, while speeding up the activation process on the others . Having the load balancer actively take the activation mechanism into consideration stabilizes the whole public node group.
Continuous deployment strategy
How to synchronize new public instances
Public instance backups should be done when the SyncState message id is identical for all public nodes. You can then choose one public node and to do a dump. Once the dump is done, create a new historical queue and empty the old queue by consuming all messages. The instance will then be ready to receive new activation messages which post-date the last dump.
Whenever you need to create a new instance, always use the latest dump. The new instance will be registered to the new historical queue. This will mean that the message id is in SyncState with the latest activation message. New activation messages will be sent to the new historical queue before they register in the old historical queue. The new historical queue will start getting all messages after the last message in old historical queue.
Adding new instances
This series of diagrams shows the best setup for scaling up when adding new public instances to the load balancer.
-
The basic idea is to always keep a spare queue (which does not have a consumer) connected to the exchange.
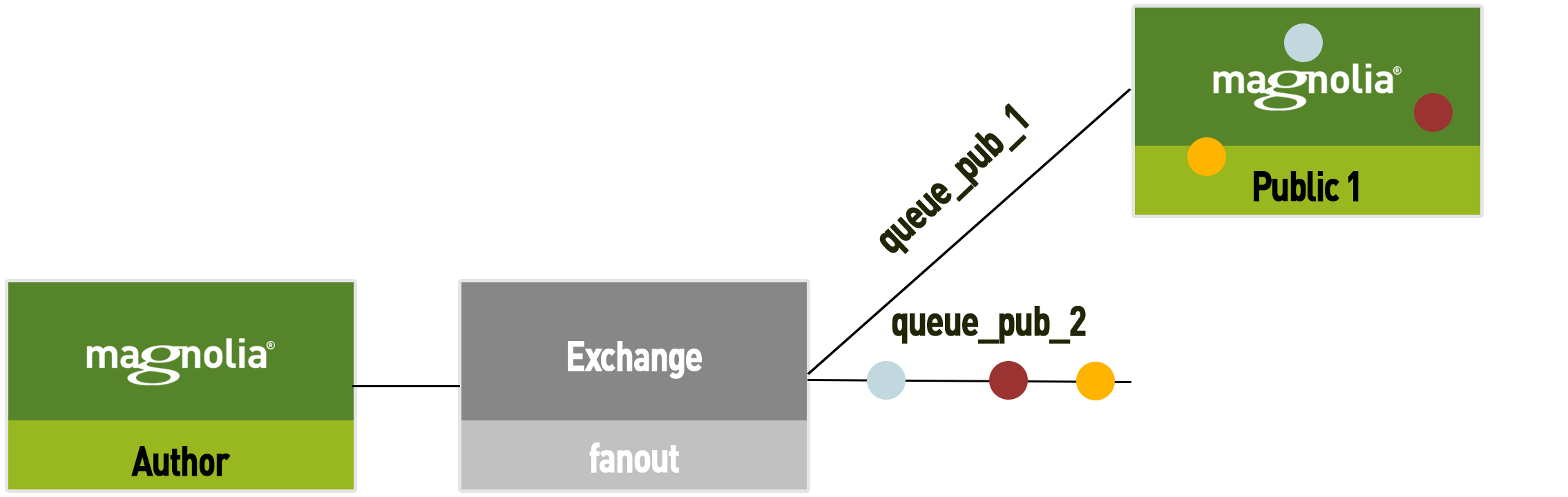
-
The spare queue stores all activation messages until a new consumer connects. The newly created instance is created with the same initial data as Public 1.
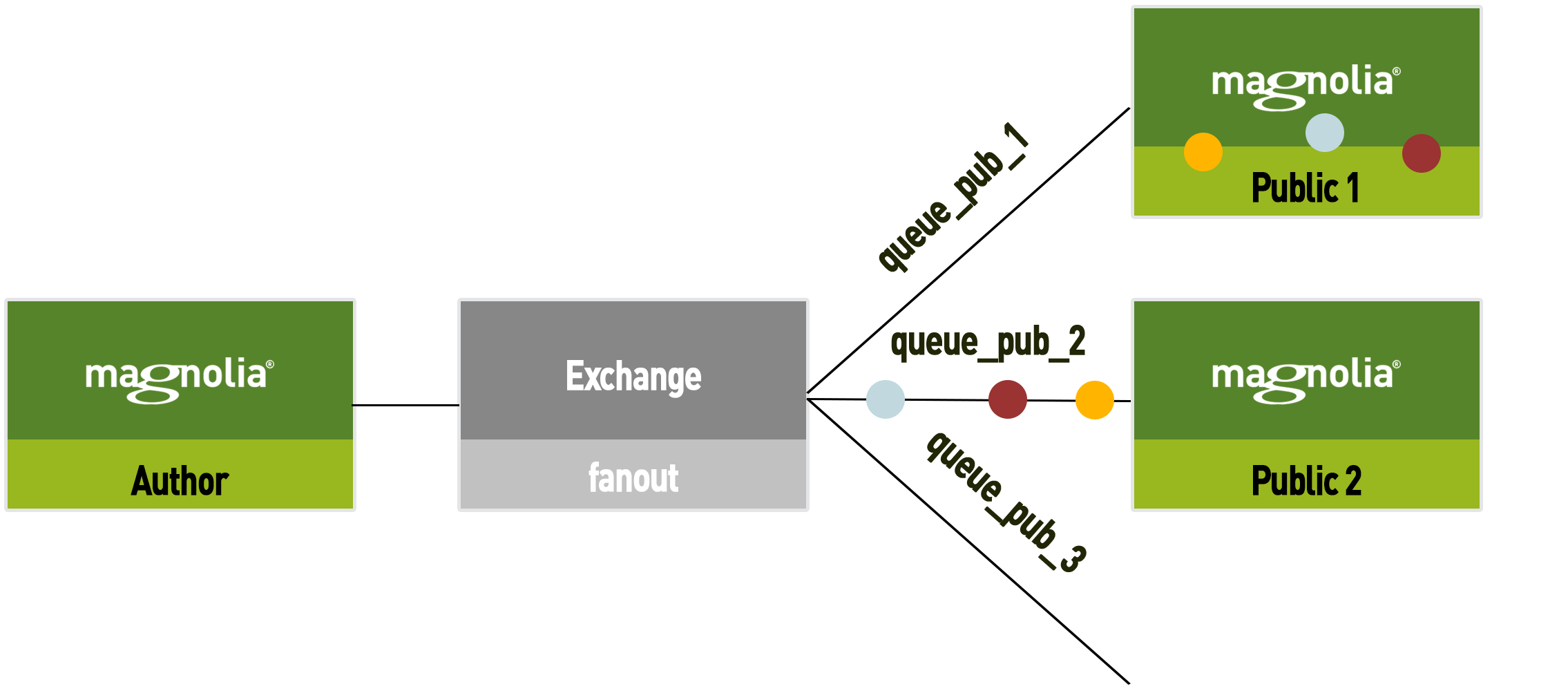
-
Public 2 is created with the same data set as Public 1. Before Public 2 starts consuming a new queue (without a consumer) is created.
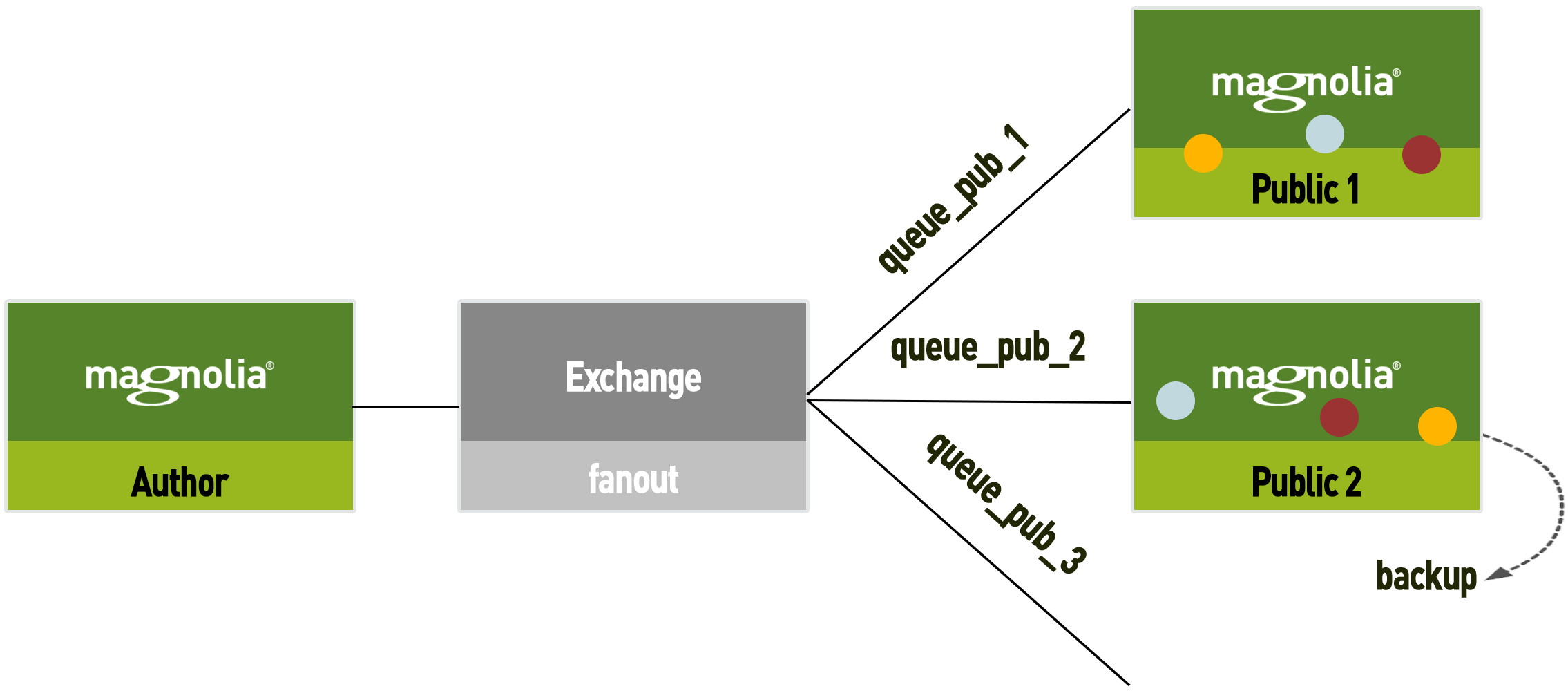
-
Once the remaining messages are consumed a backup is created. This serves as the new state for new instances. This is also the time to add the new public instance to the load balancer.
- When to do a backup?
-
Each message has a version number or tag in its header. When a new public is added it can tell the author instance or the exchange about its presence by sending its identity before consuming starts. This enables the exchange or author to create the new queue for the public instance.
From this point, all activation messages contain a new version or tag and the consumer starts consuming messages in the queue. When the consumer comes across a message with the newest version number, it does the backup.
-
Activation continues and the spare queue (queue_pub_3) is filled with new messages that represent the difference between Public 2 and newest content.
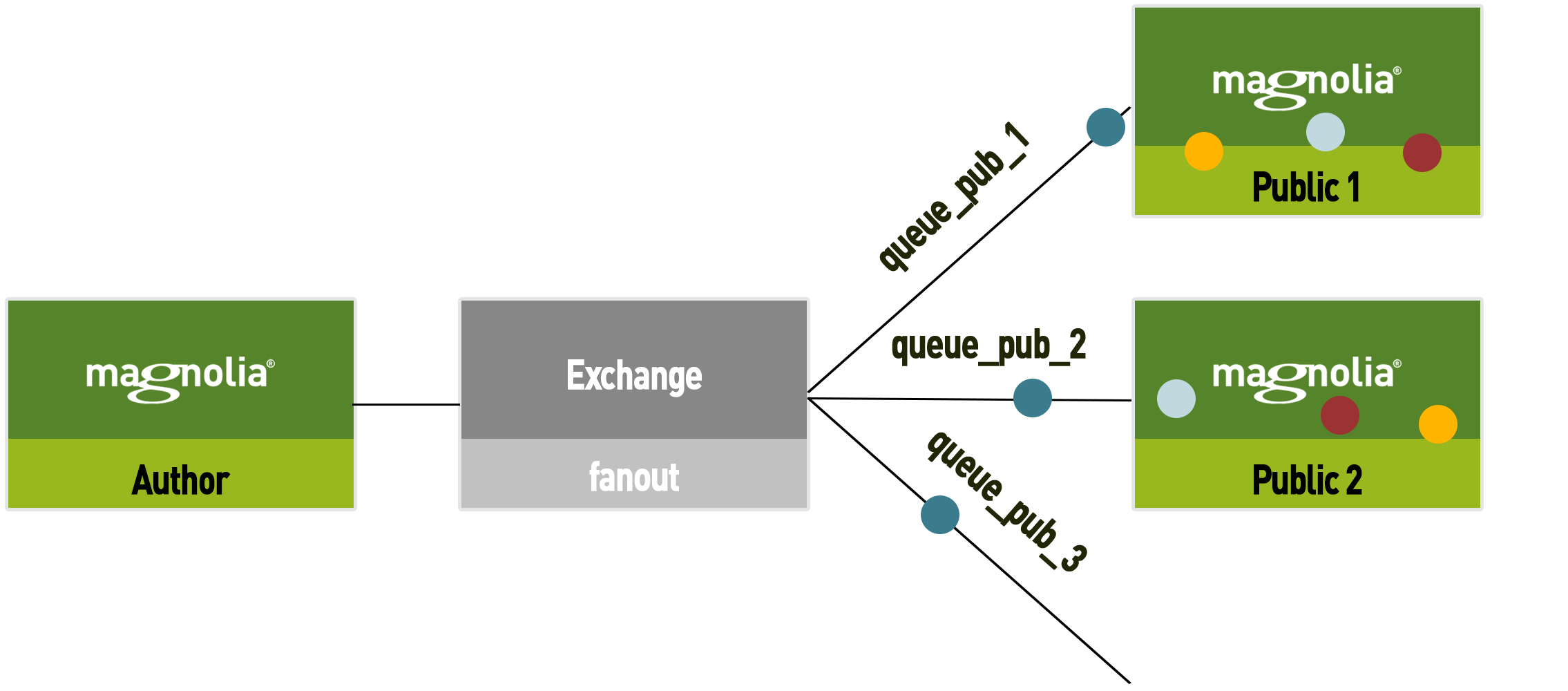
| Regular backups are needed to prevent the queue becoming too big. Whenever you do a backup on the instances the spare queue can be emptied. |
Adding a queue after backup
This example shows you how to add a new queue to the example testfanoutAck exchange:
-
Add the queue.
curl -i -u guest:guest -H "content-type:application/json" \ -XPUT -d'{"auto_delete":false,"durable":true,"arguments":{},"node":"rabbit@localhost"}' \ http://localhost:55672/api/queues/%2f/fan2 -
Declare it to be bound to correct exchange.
curl -i -u guest:guest -H "content-type:application/json" \ -d'{"routing_key":"","arguments":[]}' \ http://localhost:55672/api/bindings/%2f/fan2/testfanoutAck
ACK queue blocked by unacknowledged node
When a consumer encounters an issue because of an activation exception, the consumer stops consuming. The message is sent back to the queue with a non-ack, and an exception is sent over the ACK exchange.
To illustrate this we deleted a node on the public instance and then tried to deactivate it on the author instance.
The deletion and attempted deactivation resulted in the following error:
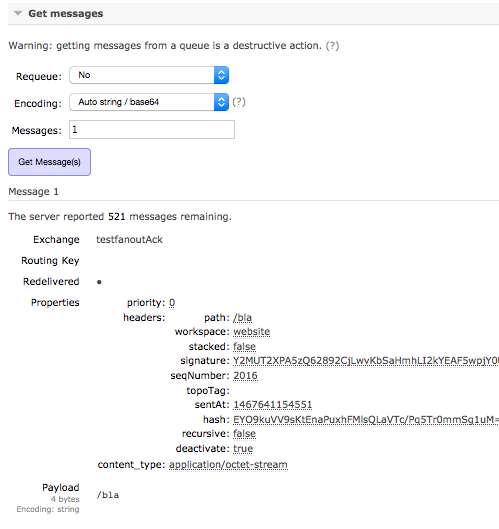
ERROR lia.rabbitmq.activation.jobs.ActivationConsumerJob: /bla
he exception is visible in the Public Monitoring app. You can see from the PathNotFoundException that the consumer did not find the path that was deleted directly of the public instance.
|

In the RabbitMQ console the:
-
Message is not consumed in the queue.
-
Message is marked unacked.
-
Consumer is gone.
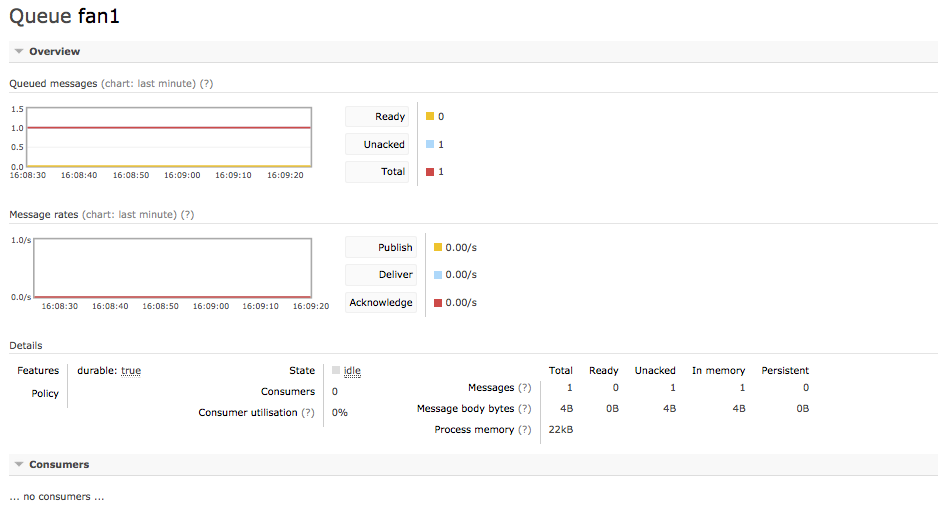
When more nodes are published into the queue they become blocked behind the unacked message.
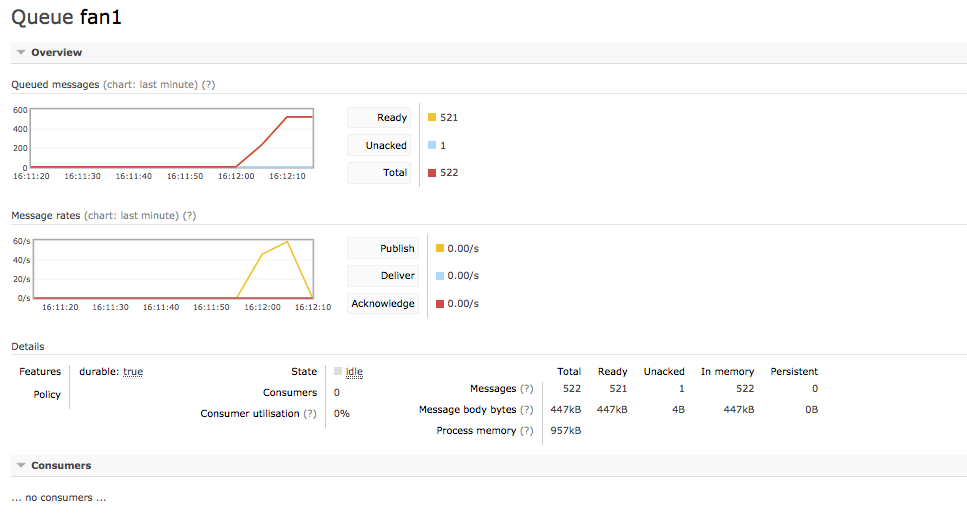
There are two ways to solve this:
-
Recreate the node on the public instance and restart the consumer.
-
The sequence number count remains correct.
-
You have to connect to the public instance and do "manual manipulation".
-
-
Remove the faulty activation message from the queue and restart the consumer.
-
This can be done remotely and there is no need to connect "manually" to the public instance.
-
Because there is one "missing" message the sequence number is lost.
-
Here’s a step-by-step solution using option 2 (because it demonstrates how to delete an unacknowledged message):
-
Close the channel in the RabbitMQ console. This acknowledges all unacknowledged messages and is needed because messages can no longer be consumed.

-
Force close the connection
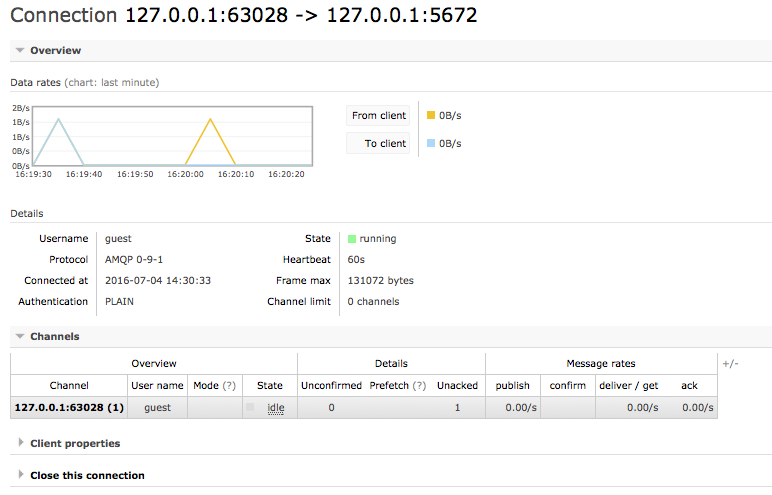
-
All messages are now acked in the queue.
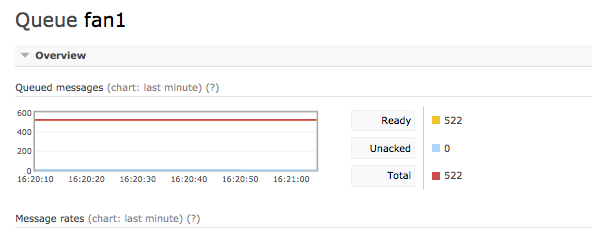
-
Consume only the "first" message.
-
Restart the consumer on the public instance.
curl http://<hostname>:<port>/<context>/.rest/rbmqClients/restartAll -
The instance is getting activated again.