Optimized Backup with Repository Splitting
| As of 2024-02-16, this page is WIP. |
This tutorial will outline the steps from creating an optimized backup mechanism. One of the most important components to optimized backup is the organization of the repository. In a scenario where you want to take backups multiples times a day it’s critical to get the amount of time spent running those backup down to a minimum.
Repository Organization
Magnolia allows for multiple repositories. In the properties file you simply configure the location of these repositories.
magnolia.repositories.home=${magnolia.home}/repositoriesHow the repositories are configured is defined by repositories.xml.
magnolia.repositories.config=WEB-INF/config/default/repositories.xmlBy default Magnolia will set up a single repository called magnolia and place all workspaces there. The down side of this is you often back up workspaces that hardly ever change each time you want to run backup. The repository copier provided by JackRabbit is the mechanism used to generate a backup. It does not offer the option to simply backup a single workspace or group of workspaces. However, it wouldn’t make sense to offer the option since trying to reconstruct the repository in a recovery scenario would be cumbersome.
A better approach is to create multiple repositories that can be backed up independently. Let’s consider the approach from Jackrabbit Repository Splitting. To make things easier let’s also use an optimized author instance called light-author. When deployed light author needs 18 workspaces. Rather than deploy into one repository let’s split these workspaces into three groups:
magnolia |
magnolia_system |
magnolia_dam |
|---|---|---|
profiles |
config |
dam |
stories |
keystore |
imaging |
tasks |
scripts |
default |
messages |
resources |
mgnlSystem |
website |
usergroups |
mgnlVersion |
default |
userroles |
version |
mgnlSystem |
users |
|
mgnlVersion |
default |
|
version |
mgnlSystem |
|
mgnlVersion |
||
version |
How to organize depends on individual needs. Simply divide the repository so that each one can be backed up independently. Typically the workspaces in magnolia_system are those workspaces which hardly ever change. This entire system repository could be recreated by simply executing a fresh installation. Where as the magnolia and magnolia_dam repositories contain those workspaces which contents editors are updating frequently. The reason to separate them is to try and keep the larger binaries in a single repo with it’s own datastore.
Backup schedule
Each repository will be backed up at a rate which corresponds to user activity.
Proposed daily schedule:
-
magnolia: 0:00, 12:15, 17:15 -
magnolia_dam: 1:00 18:00 -
magnolia_system: 2:00
The magnolia repository will be backed up 3 times a day. During lunch time, right after the end of the work day and again at midnight. Capture all changes that were made in each half of the day. The magnolia_system will be backup up at 2:00 and magnolia_dam twice a day when user activity tends to be slow. The reason for the staggered times is to avoid running backup simultaneously. Adjust you schedule according to your needs. Technically users can still be working in the system while a backup runs but it best if activity is kept to a minimum. Publishing and versioning while backing up can interfere with the process.
Configuring backup
Ideally we want to send the backup directly to a place where another backup author is waiting. The backup author is typically not running and ideally is never needed but the backup author should be setup ready to be used in a recovery scenario.
The backup author should be thought of as a temporary instance to be used until the team can repair the production instance. The database used by the backup author does not need to match the database used in production. The backup extended module has the ability to backup from any database type to any other database type. This means the backup webapp can also act as the restoration webapp for the production author. Using the same Backup Tasks app you can send the data back to the production author once all the issues have been resolved.
Example Setup
For the example setup the production author will be using MySQL database. The backup webapp will use H2 database. The production author will send its backups directly into the backups folder of the backup webapp. During the backup the data will be transformed from MySQL to H2.
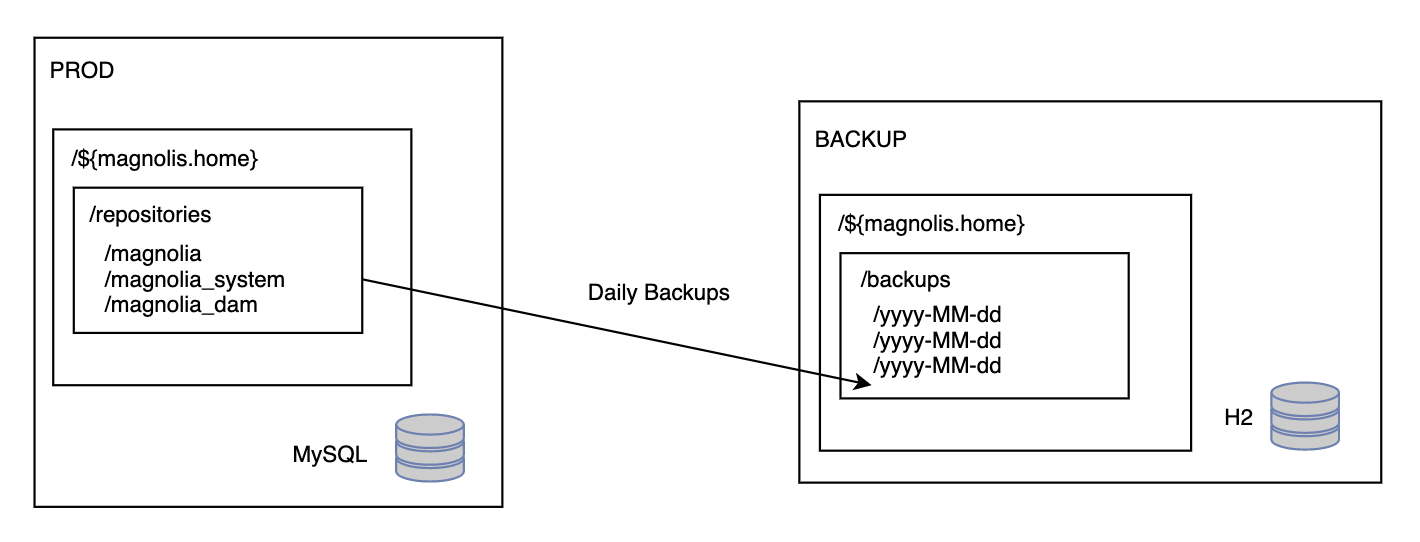
A special magnolia_control script is used with the start_backup parameter.
./magnolia_control.sh start_backupThe main purpose of the control script is to make sure the backup webapp starts with the latest version of backup data. It will scrub any files/folders left by the backup, such as, lock files, the index, workspace.xml. It’s important when starting the backup webapp the index is recreated. If backup is performed with indexing disabled the control script can reenable the index within the workspaces.
The magnoliaBackup properties file be adjusted by the control script to set the proper location of the last backup.
magnolia.repositories.home=${magnolia.home}/backups/yyyy-MM-dd/repositories| In the case of multiple backups with multiple repositories the script will sort which backups are the latest and reconstruct the entire scheme with the latest data. |